
As detailed in [1], the codebook approach extracts a histogram-type feature representing frequencies of statisitically characteristic subsequences, called codewords, in a sequence. Roughly speaking, the codebook approach consists of two main steps:
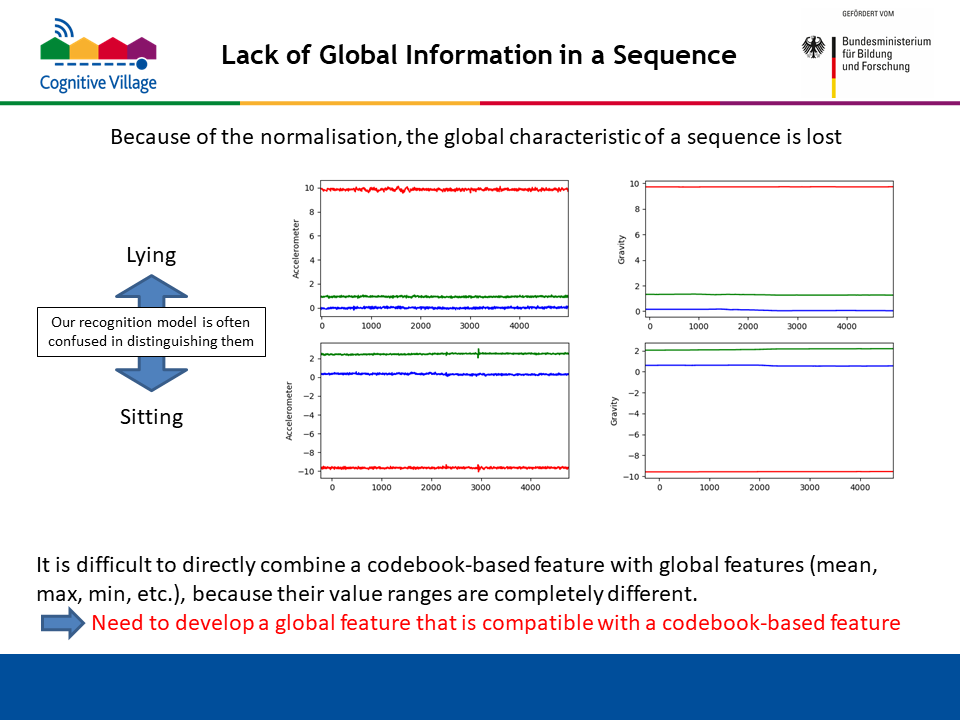
In partiular, for the CogAge dataset, one normalisation is applied to each subsequence, so that the value in every dimension always starts with zero, as illustrated in the figure below. This normalisation is useful for performing detailed analysis of subsequence shapes. In other words, it enables us to extract codewords that individually focus on "value changes" in a subsequence. However, the normalisation has a negative effect that the global characteristic of a sequence is lost. For example, as shown in the figure below, accelerometer (or gravity) sequences for the activies "Lying" and "Sitting" are almost constant. This means that normalised subsequences from such sequences start with zero on each of the three axes, and have little value changes. So, they are assigned to the same codeword, and the disctinction between between "Lying" and "Sitting" is hard using codebook-based features. Also, it is difficult to directly combine a codebook-baesd feature with global features such as the maximum, minimum, mean and standard deviation of values in a sequence. This is because value ranges of the codebook-based and global features are signifcantly different. Therefore, it is needed to develop a global feature that is compatible with a codebook-based feature.
We have implemented the above kind of global feature as a codebook-based feature using codewords of length 1, as shown in the right side of the figure below. We call this feature codebook1-based feature. Because both of the codebook-baed and codebook1-based features represent probability distributions in the form of histogram, they can be regarded as compatible with each other. One attention should be paid on the balance between the number of codewords (i.e. dimensionality) of the codebook-based feature and the one of the codebook1-based feauture. If the number of codewords of the codebook-based feature is much larger than that of the codebook1-based feauture, dimension values of the former tend to be smaller than those of the latter. That is, compared to the latter, for the former, a probability that a subsequence is assinged to one codeword is much smaller. Thus, a weight is associated with the codebook1-based feature in order to control the balance between it and the codebook-based feature. This weight is determined by two-fold cross validation.

The figure below shows the performance comparison between not-using and using codebook1-based features. Sub-graphs except for the two bottom-right ones address one sensor sequence. For each sub-graph, the blue, orange and gray pointns represent MAPs over all the 61 atomic activities, 6 state activities and 55 behaviroual activities, respectively. The leftmost points are obtained without using codebook-based1 features, while the other pointns are acquired using codebook-based1 features with 16, 32, 64 and 128 codewords. As demonstrated in this figure, the MAPs for all sensor sequences except for the magnetometer are improved. Epecially, big improvements are achieved for the accelerometer and gravity of the smarphome, the accelerometer of the smarwatch, and the accelerometer of the intelligent glasses. Hence, codebook1-based features are extracted for these sensor sequences. Under this setting, the two bottom-right sub-graphs are obtained via early fusion of sensor sequences, where codebook-based and codebook1-based features from different sensor sequences are concatenated into a high-dimensional feature. For the case where all the devices are used, the best MAP of 69.4% is achieved using codebook1-based features with 16 codewords. This setting is used to compute atomic scores to recognise composite activities.

[1] On the Generality of Codebook Approach for Sensor-based Human Activity Recognition, K. Shirahama, M. Grzegorzek, Electronics, Vol.6, No. 2, Article No. 44, 2017